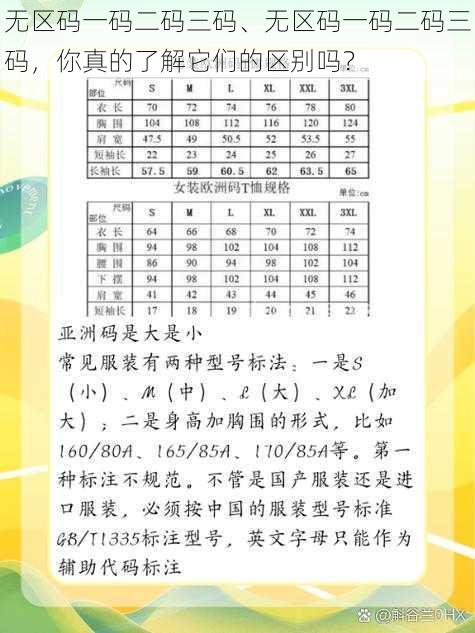
无区码一码二码三码、无区码一码二码三码,你真的了解它们的区别吗?
在当今数字化时代,我们经常会遇到各种各样的编码方式,如无区码一码、无区码二码和无区码三码等。这些编码方式在不同的领域和应用中都有着广泛的使用,但你真的了解它们之间的区别吗?将从多个方面对无区码一码、无区码二码和无区码三码进行详细的阐述,帮助你更好地理解它们的特点和区别。
编码原理
无区码一码、无区码二码和无区码三码的编码原理各不相同。无区码一码通常采用简单的字符编码方式,将字符映射为数字或其他符号。例如,常见的 ASCII 码就是一种无区码一码,它将每个字符映射为一个唯一的 7 位二进制数字。无区码二码则采用了更复杂的编码方式,通常使用多个字节来表示一个字符。例如,UTF-8 编码就是一种无区码二码,它可以使用 1 到 4 个字节来表示一个字符。无区码三码则是一种更加先进的编码方式,它可以根据字符的出现频率和上下文信息进行自适应编码,从而提高编码效率。例如,LZ77 编码和 Huffman 编码就是两种常见的无区码三码。
编码效率
编码效率是衡量一种编码方式优劣的重要指标。无区码一码的编码效率较低,因为它通常只能表示有限的字符集,而且每个字符都需要占用固定的位数。无区码二码的编码效率比无区码一码高,因为它可以使用多个字节来表示一个字符,从而可以表示更多的字符集。无区码三码的编码效率最高,因为它可以根据字符的出现频率和上下文信息进行自适应编码,从而可以在不损失太多信息的情况下,最大限度地减少编码长度。
适用范围
无区码一码、无区码二码和无区码三码的适用范围也有所不同。无区码一码通常适用于简单的字符编码,如 ASCII 码适用于英文文本的编码。无区码二码适用于需要表示大量字符集的情况,如 UTF-8 编码适用于表示中文、日文、韩文等字符集。无区码三码适用于对编码效率要求较高的情况,如在数据压缩、文件存储等领域中广泛使用的 Huffman 编码。
解码难度
解码是将编码后的信息还原为原始信息的过程。无区码一码的解码难度较低,因为它的编码方式比较简单,通常可以通过查表的方式进行解码。无区码二码的解码难度比无区码一码高,因为它的编码方式比较复杂,需要进行字节序的转换和字符的识别。无区码三码的解码难度最高,因为它的编码方式通常需要使用特定的算法进行解码,而且解码过程可能比较复杂。
应用场景
无区码一码、无区码二码和无区码三码的应用场景也有所不同。无区码一码通常用于简单的字符编码,如在电子邮件、网页等中使用的 ASCII 码。无区码二码通常用于需要表示大量字符集的情况,如在操作系统、数据库等中使用的 UTF-8 编码。无区码三码通常用于对编码效率要求较高的情况,如在数据压缩、文件存储等领域中广泛使用的 Huffman 编码。
通过对无区码一码、无区码二码和无区码三码的详细阐述,我们可以看出它们之间的区别和特点。在实际应用中,我们需要根据具体的需求和情况选择合适的编码方式。如果对编码效率要求不高,可以选择无区码一码或无区码二码;如果对编码效率要求较高,可以选择无区码三码。我们也需要注意编码的兼容性和可扩展性,以确保编码方式能够满足未来的需求。
了解无区码一码、无区码二码和无区码三码的区别和特点对于我们正确使用编码方式非常重要。希望能够帮助读者更好地理解这些编码方式,为实际应用提供有益的参考。